import pandas as pd # For Data Manipulation
import numpy as np # For Data Manipulation
import matplotlib.pyplot as plt # For Visualization
import seaborn as sns # For Visualization
import sklearn # For Machine Learning
import warnings
warnings.filterwarnings('ignore')
# Plotnine is a clone of ggplot2 in R
from plotnine import *
# lets-plot is another clone of ggplot2
# from lets_plot import *
Exploratory Data Analysis in Python
Exploratory Data Analysis in Python
1 Introduction
The objective of this document is to introduce the necessary functions from pandas library in Python for data manipulation and matplotlib and seaborn libraries for data visualization. There are basically six functions - select(), filter(), mutate(), arrange(), group_by(), and summarize() - from dplyr package of tidyverse ecosystem that are very much necessary for data manipulation. These six functions can be used for 80% of data manipulation problems. In this document, we will compare the above six functions from dplyr with the equivalent pandas functions. Additionally, this handout also compares some other Python packages, particularly plotnine library that can be used to apply ggplot in Python.
2 Loading Necessary Python Packages
Python programming in RMarkdown is used to analyse the data. In some cases, the R Programmingis also used. In this section, the necessary python packages/modules are imported.
3 Setting/Changing Working Directory
import os
os.getcwd()
os.listdir()4 Importing the Dataset
Being able to import the dataset into your text editor or IDE such as VS Code or RStudio is an important data analytics skill. Data reside in many places and in many forms. Different kinds of data from different sources need to be imported. For example - you can import a dataset from your local machine or website or database. Sometimes, we need to import data from social media such as Twitter, Youtube and Facebook. Therefore, knowing how to import data from many different sources is a very critical skill of data scientists.
# Importing Dataset
product = pd.read_csv(
"https://raw.githubusercontent.com/msharifbd/DATA/main/Al-Bundy_raw-data.csv")5 Learning About the Metadata
Metadata is data about data. Once we import a dataset into our text editor, we need to study the dataset very well. For example - we need to know how many features and cases the dataset has. We also need to know the types of the features. Many types the features are not in appropriate type; then, we need to change them into appropriate type. Moreover, we need to check whether the dataset contains missing data and make decision about how to deal with those missing data. To sum up, learning about the metadata is a very important step before you start processing your data.
# Metadata of the dataset
product.shape(14967, 14)print('The total number of rows and columns of the product data is \
{} and {} respectively.'.format(product.shape[0], product.shape[1]))The total number of rows and columns of the product data is 14967 and 14 respectively.product.count()[0] # counting the number of rows in the datasetnp.int64(14967)product.columnsIndex(['InvoiceNo', 'Date', 'Country', 'ProductID', 'Shop', 'Gender',
'Size (US)', 'Size (Europe)', 'Size (UK)', 'UnitPrice', 'Discount',
'Year', 'Month', 'SalePrice'],
dtype='object')product.dtypesInvoiceNo int64
Date object
Country object
ProductID int64
Shop object
Gender object
Size (US) float64
Size (Europe) object
Size (UK) float64
UnitPrice int64
Discount float64
Year int64
Month int64
SalePrice float64
dtype: objectproduct.head() InvoiceNo Date Country ... Year Month SalePrice
0 52389 1/1/2014 United Kingdom ... 2014 1 159.0
1 52390 1/1/2014 United States ... 2014 1 159.2
2 52391 1/1/2014 Canada ... 2014 1 119.2
3 52392 1/1/2014 United States ... 2014 1 159.0
4 52393 1/1/2014 United Kingdom ... 2014 1 159.0
[5 rows x 14 columns]product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 14967 non-null int64
1 Date 14967 non-null object
2 Country 14967 non-null object
3 ProductID 14967 non-null int64
4 Shop 14967 non-null object
5 Gender 14967 non-null object
6 Size (US) 14967 non-null float64
7 Size (Europe) 14967 non-null object
8 Size (UK) 14967 non-null float64
9 UnitPrice 14967 non-null int64
10 Discount 14967 non-null float64
11 Year 14967 non-null int64
12 Month 14967 non-null int64
13 SalePrice 14967 non-null float64
dtypes: float64(4), int64(5), object(5)
memory usage: 1.6+ MB6 Cleaning the Dataset
# Changing the names of the columns to uppercase
product.rename(columns = str.upper, inplace = True)
product.columnsIndex(['INVOICENO', 'DATE', 'COUNTRY', 'PRODUCTID', 'SHOP', 'GENDER',
'SIZE (US)', 'SIZE (EUROPE)', 'SIZE (UK)', 'UNITPRICE', 'DISCOUNT',
'YEAR', 'MONTH', 'SALEPRICE'],
dtype='object')new_column = product.columns \
.str.replace("(", '').str.replace(")", "") \
.str.replace(' ','_') # Cleaning the names of the variables
new_columnIndex(['INVOICENO', 'DATE', 'COUNTRY', 'PRODUCTID', 'SHOP', 'GENDER',
'SIZE_US', 'SIZE_EUROPE', 'SIZE_UK', 'UNITPRICE', 'DISCOUNT', 'YEAR',
'MONTH', 'SALEPRICE'],
dtype='object')# Replacing whitespace in the names of the variables
col_name = product.columns.str.replace(' ','_')
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null int64
1 DATE 14967 non-null object
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null int64
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE (US) 14967 non-null float64
7 SIZE (EUROPE) 14967 non-null object
8 SIZE (UK) 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null int64
13 SALEPRICE 14967 non-null float64
dtypes: float64(4), int64(5), object(5)
memory usage: 1.6+ MBproduct.columns = new_column # Changing all column names
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null int64
1 DATE 14967 non-null object
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null int64
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null int64
13 SALEPRICE 14967 non-null float64
dtypes: float64(4), int64(5), object(5)
memory usage: 1.6+ MBproduct.head() INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
0 52389 1/1/2014 United Kingdom ... 2014 1 159.0
1 52390 1/1/2014 United States ... 2014 1 159.2
2 52391 1/1/2014 Canada ... 2014 1 119.2
3 52392 1/1/2014 United States ... 2014 1 159.0
4 52393 1/1/2014 United Kingdom ... 2014 1 159.0
[5 rows x 14 columns]6.1 Changing the Types of the Variables
There are several types of data in Python as it is in R. Table Table 1 lists the data types in python.
| Python Data Type | Data Nature |
|---|---|
| float64 | Real Numbers |
| category | cateogries |
| datetime64 | Date Times |
| int64 | Integers |
| bool | True or False |
| string | Text |
# Changing the DATE variable from object to date
product['DATE'] = pd.to_datetime(product['DATE'])
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null int64
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null int64
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null int64
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(5), object(4)
memory usage: 1.6+ MB# converting integer to object
product.INVOICENO = product.INVOICENO.astype(str)
product[['MONTH', 'PRODUCTID']] = product[['MONTH', 'PRODUCTID']].astype(str)
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(7)
memory usage: 1.6+ MB7 Tidyverse and Pandas Eqivalent Functions
Table Table 2 compares the tidyverse and pandas equivalent functions. These functions are very much important to perform data analysis in both R and Python.
| tidyverse function | pandas function |
|---|---|
| filter () | query () |
| arrange () | sort_values () |
| select () | filter () or loc () |
| rename () | rename () |
| mutate () | assign () |
| group_by () | groupby () |
| summarize () | agg () |
7.1 select () Equivalent in Python - Accessing Columns
prod2 = product[['YEAR','SALEPRICE', 'DISCOUNT', 'UNITPRICE']]
prod2.head() YEAR SALEPRICE DISCOUNT UNITPRICE
0 2014 159.0 0.0 159
1 2014 159.2 0.2 199
2 2014 119.2 0.2 149
3 2014 159.0 0.0 159
4 2014 159.0 0.0 159product.loc[:,['YEAR','SALEPRICE', 'DISCOUNT', 'UNITPRICE']] YEAR SALEPRICE DISCOUNT UNITPRICE
0 2014 159.0 0.0 159
1 2014 159.2 0.2 199
2 2014 119.2 0.2 149
3 2014 159.0 0.0 159
4 2014 159.0 0.0 159
... ... ... ... ...
14962 2016 139.0 0.0 139
14963 2016 149.0 0.0 149
14964 2016 125.3 0.3 179
14965 2016 199.0 0.0 199
14966 2016 125.1 0.1 139
[14967 rows x 4 columns]product.loc[0:5,['YEAR','SALEPRICE', 'DISCOUNT', 'UNITPRICE']] YEAR SALEPRICE DISCOUNT UNITPRICE
0 2014 159.0 0.0 159
1 2014 159.2 0.2 199
2 2014 119.2 0.2 149
3 2014 159.0 0.0 159
4 2014 159.0 0.0 159
5 2014 159.0 0.0 159product.filter(['YEAR','SALEPRICE', 'DISCOUNT', 'UNITPRICE']) YEAR SALEPRICE DISCOUNT UNITPRICE
0 2014 159.0 0.0 159
1 2014 159.2 0.2 199
2 2014 119.2 0.2 149
3 2014 159.0 0.0 159
4 2014 159.0 0.0 159
... ... ... ... ...
14962 2016 139.0 0.0 139
14963 2016 149.0 0.0 149
14964 2016 125.3 0.3 179
14965 2016 199.0 0.0 199
14966 2016 125.1 0.1 139
[14967 rows x 4 columns]# Regular Expression (Regex)
product.filter(regex = "PRICE$") # Ends with Price UNITPRICE SALEPRICE
0 159 159.0
1 199 159.2
2 149 119.2
3 159 159.0
4 159 159.0
... ... ...
14962 139 139.0
14963 149 149.0
14964 179 125.3
14965 199 199.0
14966 139 125.1
[14967 rows x 2 columns]product.filter(regex = "^SIZE") # Starts with SIZE SIZE_US SIZE_EUROPE SIZE_UK
0 11.0 44 10.5
1 11.5 44-45 11.0
2 9.5 42-43 9.0
3 9.5 40 7.5
4 9.0 39-40 7.0
... ... ... ...
14962 9.5 42-43 9.0
14963 12.0 42-43 10.0
14964 10.5 43-44 10.0
14965 9.5 40 7.5
14966 6.5 37 4.5
[14967 rows x 3 columns]product.filter(regex = "PRICE") # Contains the word Price UNITPRICE SALEPRICE
0 159 159.0
1 199 159.2
2 149 119.2
3 159 159.0
4 159 159.0
... ... ...
14962 139 139.0
14963 149 149.0
14964 179 125.3
14965 199 199.0
14966 139 125.1
[14967 rows x 2 columns]product.select_dtypes('object') INVOICENO COUNTRY PRODUCTID SHOP GENDER SIZE_EUROPE MONTH
0 52389 United Kingdom 2152 UK2 Male 44 1
1 52390 United States 2230 US15 Male 44-45 1
2 52391 Canada 2160 CAN7 Male 42-43 1
3 52392 United States 2234 US6 Female 40 1
4 52393 United Kingdom 2222 UK4 Female 39-40 1
... ... ... ... ... ... ... ...
14962 65773 United Kingdom 2154 UK2 Male 42-43 12
14963 65774 United States 2181 US12 Female 42-43 12
14964 65775 Canada 2203 CAN6 Male 43-44 12
14965 65776 Germany 2231 GER1 Female 40 12
14966 65777 Germany 2156 GER1 Female 37 12
[14967 rows x 7 columns]product.select_dtypes('int') UNITPRICE YEAR
0 159 2014
1 199 2014
2 149 2014
3 159 2014
4 159 2014
... ... ...
14962 139 2016
14963 149 2016
14964 179 2016
14965 199 2016
14966 139 2016
[14967 rows x 2 columns]product.loc[:,product.columns.str.startswith('SIZE')] SIZE_US SIZE_EUROPE SIZE_UK
0 11.0 44 10.5
1 11.5 44-45 11.0
2 9.5 42-43 9.0
3 9.5 40 7.5
4 9.0 39-40 7.0
... ... ... ...
14962 9.5 42-43 9.0
14963 12.0 42-43 10.0
14964 10.5 43-44 10.0
14965 9.5 40 7.5
14966 6.5 37 4.5
[14967 rows x 3 columns]product.loc[:,product.columns.str.contains('PRICE')] UNITPRICE SALEPRICE
0 159 159.0
1 199 159.2
2 149 119.2
3 159 159.0
4 159 159.0
... ... ...
14962 139 139.0
14963 149 149.0
14964 179 125.3
14965 199 199.0
14966 139 125.1
[14967 rows x 2 columns]product.loc[:,product.columns.str.endswith('PRICE')] UNITPRICE SALEPRICE
0 159 159.0
1 199 159.2
2 149 119.2
3 159 159.0
4 159 159.0
... ... ...
14962 139 139.0
14963 149 149.0
14964 179 125.3
14965 199 199.0
14966 139 125.1
[14967 rows x 2 columns]# Dropping some columns
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(7)
memory usage: 1.6+ MBproduct.drop(columns = ['SIZE_EUROPE', 'SIZE_UK'], axis = 1) INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
0 52389 2014-01-01 United Kingdom ... 2014 1 159.0
1 52390 2014-01-01 United States ... 2014 1 159.2
2 52391 2014-01-01 Canada ... 2014 1 119.2
3 52392 2014-01-01 United States ... 2014 1 159.0
4 52393 2014-01-01 United Kingdom ... 2014 1 159.0
... ... ... ... ... ... ... ...
14962 65773 2016-12-31 United Kingdom ... 2016 12 139.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
14964 65775 2016-12-31 Canada ... 2016 12 125.3
14965 65776 2016-12-31 Germany ... 2016 12 199.0
14966 65777 2016-12-31 Germany ... 2016 12 125.1
[14967 rows x 12 columns]product.drop(columns = ['SIZE_EUROPE', 'SIZE_UK'], axis = 1) \
.pipe(lambda x: x.info())<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 UNITPRICE 14967 non-null int64
8 DISCOUNT 14967 non-null float64
9 YEAR 14967 non-null int64
10 MONTH 14967 non-null object
11 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(3), int64(2), object(6)
memory usage: 1.4+ MB7.1.1 Rearranging Columns
# Sorting Alphabetically
product.reindex(sorted(product.columns), axis = 1) COUNTRY DATE DISCOUNT ... SIZE_US UNITPRICE YEAR
0 United Kingdom 2014-01-01 0.0 ... 11.0 159 2014
1 United States 2014-01-01 0.2 ... 11.5 199 2014
2 Canada 2014-01-01 0.2 ... 9.5 149 2014
3 United States 2014-01-01 0.0 ... 9.5 159 2014
4 United Kingdom 2014-01-01 0.0 ... 9.0 159 2014
... ... ... ... ... ... ... ...
14962 United Kingdom 2016-12-31 0.0 ... 9.5 139 2016
14963 United States 2016-12-31 0.0 ... 12.0 149 2016
14964 Canada 2016-12-31 0.3 ... 10.5 179 2016
14965 Germany 2016-12-31 0.0 ... 9.5 199 2016
14966 Germany 2016-12-31 0.1 ... 6.5 139 2016
[14967 rows x 14 columns]# Sorting As You Want (ASY)
product.columns.to_list()['INVOICENO', 'DATE', 'COUNTRY', 'PRODUCTID', 'SHOP', 'GENDER', 'SIZE_US', 'SIZE_EUROPE', 'SIZE_UK', 'UNITPRICE', 'DISCOUNT', 'YEAR', 'MONTH', 'SALEPRICE']col_first = ['YEAR','MONTH']
col_rest = product.columns.difference(col_first, sort=False).to_list()
product2 = product[col_first + col_rest]
product2.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 YEAR 14967 non-null int64
1 MONTH 14967 non-null object
2 INVOICENO 14967 non-null object
3 DATE 14967 non-null datetime64[ns]
4 COUNTRY 14967 non-null object
5 PRODUCTID 14967 non-null object
6 SHOP 14967 non-null object
7 GENDER 14967 non-null object
8 SIZE_US 14967 non-null float64
9 SIZE_EUROPE 14967 non-null object
10 SIZE_UK 14967 non-null float64
11 UNITPRICE 14967 non-null int64
12 DISCOUNT 14967 non-null float64
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(7)
memory usage: 1.6+ MB7.2 filter () Equivalent in Python - Accessing Rows
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(7)
memory usage: 1.6+ MBproduct.COUNTRY.value_counts()COUNTRY
United States 5886
Germany 4392
Canada 2952
United Kingdom 1737
Name: count, dtype: int64product['YEAR'].unique()array([2014, 2015, 2016])product['YEAR'].value_counts()YEAR
2016 7366
2015 4848
2014 2753
Name: count, dtype: int64product.query('COUNTRY == "United States"') INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
8 52397 2014-01-02 United States ... 2014 1 139.0
10 52399 2014-01-02 United States ... 2014 1 129.0
... ... ... ... ... ... ... ...
14956 65767 2016-12-31 United States ... 2016 12 139.0
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
[5886 rows x 14 columns]product.query('COUNTRY == "United States" | COUNTRY == "Canada"') INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
2 52391 2014-01-01 Canada ... 2014 1 119.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
7 52396 2014-01-02 Canada ... 2014 1 169.0
... ... ... ... ... ... ... ...
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
14964 65775 2016-12-31 Canada ... 2016 12 125.3
[8838 rows x 14 columns]product.query("COUNTRY in ['United States', 'Canada']") INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
2 52391 2014-01-01 Canada ... 2014 1 119.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
7 52396 2014-01-02 Canada ... 2014 1 169.0
... ... ... ... ... ... ... ...
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
14964 65775 2016-12-31 Canada ... 2016 12 125.3
[8838 rows x 14 columns]product.query("COUNTRY == 'United States' & YEAR == 2016") INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
7610 59206 2016-01-02 United States ... 2016 1 132.3
7613 59209 2016-01-02 United States ... 2016 1 127.2
7617 59213 2016-01-02 United States ... 2016 1 125.3
7618 59214 2016-01-02 United States ... 2016 1 151.2
7619 59214 2016-01-02 United States ... 2016 1 151.2
... ... ... ... ... ... ... ...
14956 65767 2016-12-31 United States ... 2016 12 139.0
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
[2935 rows x 14 columns]product.query("COUNTRY == 'United States' & YEAR in [2015,2016]") INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
2753 54725 2015-01-01 United States ... 2015 1 179.0
2754 54726 2015-01-01 United States ... 2015 1 169.0
2755 54727 2015-01-01 United States ... 2015 1 116.1
2761 54733 2015-01-02 United States ... 2015 1 179.0
2766 54738 2015-01-02 United States ... 2015 1 199.0
... ... ... ... ... ... ... ...
14956 65767 2016-12-31 United States ... 2016 12 139.0
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
[4859 rows x 14 columns]product.loc[(product['COUNTRY'] == "United States")] INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
8 52397 2014-01-02 United States ... 2014 1 139.0
10 52399 2014-01-02 United States ... 2014 1 129.0
... ... ... ... ... ... ... ...
14956 65767 2016-12-31 United States ... 2016 12 139.0
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
[5886 rows x 14 columns]product.loc[product['COUNTRY'].isin(["United States", "Canada"])] INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
2 52391 2014-01-01 Canada ... 2014 1 119.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
7 52396 2014-01-02 Canada ... 2014 1 169.0
... ... ... ... ... ... ... ...
14959 65770 2016-12-31 United States ... 2016 12 119.2
14960 65771 2016-12-31 United States ... 2016 12 189.0
14961 65772 2016-12-31 United States ... 2016 12 129.0
14963 65774 2016-12-31 United States ... 2016 12 149.0
14964 65775 2016-12-31 Canada ... 2016 12 125.3
[8838 rows x 14 columns]product.loc[product['COUNTRY'] \
.isin(["United States", "Canada"]) & (product['YEAR'] == 2014)] INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
2 52391 2014-01-01 Canada ... 2014 1 119.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
7 52396 2014-01-02 Canada ... 2014 1 169.0
... ... ... ... ... ... ... ...
2739 54713 2014-12-30 United States ... 2014 12 189.0
2745 54718 2014-12-31 Canada ... 2014 12 151.2
2746 54719 2014-12-31 United States ... 2014 12 199.0
2748 54721 2014-12-31 Canada ... 2014 12 74.5
2749 54722 2014-12-31 United States ... 2014 12 118.3
[1649 rows x 14 columns]product.loc[(product['COUNTRY'] == "United States") & (product["YEAR"] == 2014)] INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
1 52390 2014-01-01 United States ... 2014 1 159.2
3 52392 2014-01-01 United States ... 2014 1 159.0
5 52394 2014-01-01 United States ... 2014 1 159.0
8 52397 2014-01-02 United States ... 2014 1 139.0
10 52399 2014-01-02 United States ... 2014 1 129.0
... ... ... ... ... ... ... ...
2731 54705 2014-12-29 United States ... 2014 12 179.0
2734 54708 2014-12-30 United States ... 2014 12 159.0
2739 54713 2014-12-30 United States ... 2014 12 189.0
2746 54719 2014-12-31 United States ... 2014 12 199.0
2749 54722 2014-12-31 United States ... 2014 12 118.3
[1027 rows x 14 columns]7.2.1 loc[] Function can be used both for Slicing (selecting Rows) and Selecting Columns
product.loc[
product['COUNTRY'] == 'United States',
['COUNTRY', "UNITPRICE", "SALEPRICE"]] COUNTRY UNITPRICE SALEPRICE
1 United States 199 159.2
3 United States 159 159.0
5 United States 159 159.0
8 United States 139 139.0
10 United States 129 129.0
... ... ... ...
14956 United States 139 139.0
14959 United States 149 119.2
14960 United States 189 189.0
14961 United States 129 129.0
14963 United States 149 149.0
[5886 rows x 3 columns]7.3 arrange () Equivalent in Python - Sorting or Arranging Rows
product.sort_values(by = ['MONTH']) INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
0 52389 2014-01-01 United Kingdom ... 2014 1 159.0
2862 54831 2015-01-13 Germany ... 2015 1 169.0
2863 54832 2015-01-13 Germany ... 2015 1 125.1
2864 54833 2015-01-13 United States ... 2015 1 135.2
2865 54834 2015-01-13 Germany ... 2015 1 149.0
... ... ... ... ... ... ... ...
13225 64202 2016-09-28 Canada ... 2016 9 189.0
13224 64201 2016-09-28 Germany ... 2016 9 149.0
13223 64200 2016-09-28 Canada ... 2016 9 199.0
13235 64210 2016-09-29 United States ... 2016 9 135.2
12749 63775 2016-09-08 Germany ... 2016 9 139.0
[14967 rows x 14 columns]product.sort_values(by = ['MONTH'], ascending = False) INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
13162 64145 2016-09-26 United Kingdom ... 2016 9 90.3
5946 57674 2015-09-12 United States ... 2015 9 159.0
5944 57672 2015-09-12 Canada ... 2015 9 179.0
5943 57671 2015-09-12 Germany ... 2015 9 159.0
5942 57670 2015-09-12 Canada ... 2015 9 179.0
... ... ... ... ... ... ... ...
3037 54995 2015-01-29 United States ... 2015 1 103.2
3038 54996 2015-01-30 Canada ... 2015 1 161.1
3039 54997 2015-01-30 Canada ... 2015 1 84.5
3040 54997 2015-01-30 Canada ... 2015 1 169.0
0 52389 2014-01-01 United Kingdom ... 2014 1 159.0
[14967 rows x 14 columns]product.sort_values(by = ['MONTH', 'SALEPRICE']) INVOICENO DATE COUNTRY ... YEAR MONTH SALEPRICE
33 52414 2014-01-05 Germany ... 2014 1 64.5
177 52533 2014-01-25 Canada ... 2014 1 64.5
185 52539 2014-01-26 United Kingdom ... 2014 1 64.5
194 52548 2014-01-27 United Kingdom ... 2014 1 64.5
2762 54734 2015-01-02 Germany ... 2015 1 64.5
... ... ... ... ... ... ... ...
13245 64219 2016-09-29 United Kingdom ... 2016 9 199.0
13246 64220 2016-09-29 United States ... 2016 9 199.0
13248 64222 2016-09-29 United States ... 2016 9 199.0
13251 64224 2016-09-29 Germany ... 2016 9 199.0
13272 64244 2016-09-30 United States ... 2016 9 199.0
[14967 rows x 14 columns]7.4 rename () Equivalent in Python - Renaming Column Names
We already did some renaming of the columns using str. function. Here we use rename () function to change the name of the columns.
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(7)
memory usage: 1.6+ MBproduct.rename( columns =
{'SIZE_(EUROPE)': 'SIZE_EUROPE',
'SIZE_(UK)' : 'SIZE_UK'}) \
.pipe(lambda x: x.info())<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
dtypes: datetime64[ns](1), float64(4), int64(2), object(7)
memory usage: 1.6+ MB7.5 mutate () Equivalent in Python - Creating New Columns (Variables)
product['NECOLUMN'] = 5
product.head() INVOICENO DATE COUNTRY ... MONTH SALEPRICE NECOLUMN
0 52389 2014-01-01 United Kingdom ... 1 159.0 5
1 52390 2014-01-01 United States ... 1 159.2 5
2 52391 2014-01-01 Canada ... 1 119.2 5
3 52392 2014-01-01 United States ... 1 159.0 5
4 52393 2014-01-01 United Kingdom ... 1 159.0 5
[5 rows x 15 columns]product.drop(columns = ['NECOLUMN'], axis = 1, inplace = True) product['SALEPRICE2'] = product['UNITPRICE']*(1-product['DISCOUNT'])
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
14 SALEPRICE2 14967 non-null float64
dtypes: datetime64[ns](1), float64(5), int64(2), object(7)
memory usage: 1.7+ MB# Using the assign () function
product[['PRODUCTID', 'UNITPRICE', 'DISCOUNT']] \
.assign(SALEPRICE3 = lambda x: x.UNITPRICE*(1-x.DISCOUNT)) \
.head(5) PRODUCTID UNITPRICE DISCOUNT SALEPRICE3
0 2152 159 0.0 159.0
1 2230 199 0.2 159.2
2 2160 149 0.2 119.2
3 2234 159 0.0 159.0
4 2222 159 0.0 159.07.6 group_by () and summarize () Equivalent in Python - Summarizing Data
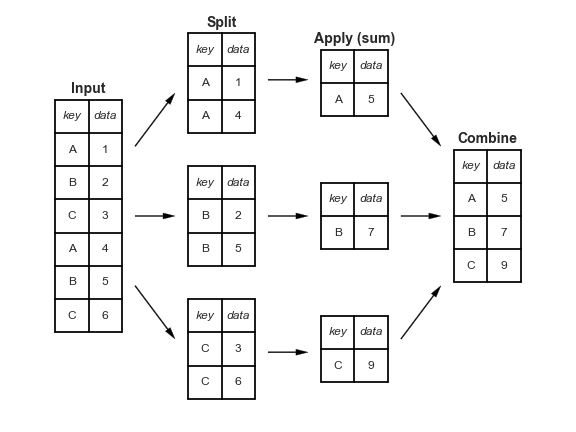
Figure Figure 1 presents the split-apply-combine principle in group_by () and summarize () functions.
product.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14967 entries, 0 to 14966
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 INVOICENO 14967 non-null object
1 DATE 14967 non-null datetime64[ns]
2 COUNTRY 14967 non-null object
3 PRODUCTID 14967 non-null object
4 SHOP 14967 non-null object
5 GENDER 14967 non-null object
6 SIZE_US 14967 non-null float64
7 SIZE_EUROPE 14967 non-null object
8 SIZE_UK 14967 non-null float64
9 UNITPRICE 14967 non-null int64
10 DISCOUNT 14967 non-null float64
11 YEAR 14967 non-null int64
12 MONTH 14967 non-null object
13 SALEPRICE 14967 non-null float64
14 SALEPRICE2 14967 non-null float64
dtypes: datetime64[ns](1), float64(5), int64(2), object(7)
memory usage: 1.7+ MBproduct.groupby(['COUNTRY']) ['UNITPRICE'].mean()COUNTRY
Canada 164.691057
Germany 164.163934
United Kingdom 165.614853
United States 163.490316
Name: UNITPRICE, dtype: float64product.groupby(['COUNTRY']) [['UNITPRICE', 'SALEPRICE']].mean() UNITPRICE SALEPRICE
COUNTRY
Canada 164.691057 144.228963
Germany 164.163934 143.574658
United Kingdom 165.614853 145.505872
United States 163.490316 143.727421product.groupby(['COUNTRY']) [['UNITPRICE', 'SALEPRICE']] \
.agg(np.mean)<string>:3: FutureWarning: The provided callable <function mean at 0x00000199A8E536A0> is currently using DataFrameGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
UNITPRICE SALEPRICE
COUNTRY
Canada 164.691057 144.228963
Germany 164.163934 143.574658
United Kingdom 165.614853 145.505872
United States 163.490316 143.727421product.groupby(['COUNTRY']) [['UNITPRICE', 'SALEPRICE']] \
.agg("mean") UNITPRICE SALEPRICE
COUNTRY
Canada 164.691057 144.228963
Germany 164.163934 143.574658
United Kingdom 165.614853 145.505872
United States 163.490316 143.727421
product.groupby(['COUNTRY']) [['UNITPRICE', 'SALEPRICE']] \
.agg(AVG_UNITPRICE = ("UNITPRICE", "mean"),
AVG_LISTPRICE = ("SALEPRICE", "mean")) AVG_UNITPRICE AVG_LISTPRICE
COUNTRY
Canada 164.691057 144.228963
Germany 164.163934 143.574658
United Kingdom 165.614853 145.505872
United States 163.490316 143.727421
product.groupby(['COUNTRY']) [['UNITPRICE', 'SALEPRICE']] \
.agg(AVG_UNITPRICE = ("UNITPRICE", "mean"),
AVG_LISTPRICE = ("SALEPRICE", "mean"),
TOTALN = ("SALEPRICE", "size"), # size function for n
TOTALOBS = ("SALEPRICE", "count") # count function for n
) AVG_UNITPRICE AVG_LISTPRICE TOTALN TOTALOBS
COUNTRY
Canada 164.691057 144.228963 2952 2952
Germany 164.163934 143.574658 4392 4392
United Kingdom 165.614853 145.505872 1737 1737
United States 163.490316 143.727421 5886 5886# Combining Several Pandas Functions together
product.groupby(['COUNTRY']) [['UNITPRICE', 'SALEPRICE']] \
.agg(AVG_UNITPRICE = ("UNITPRICE", "mean"),
AVG_LISTPRICE = ("SALEPRICE", "mean"),
TOTALN = ("SALEPRICE", "size"), # size function for n
TOTALOBS = ("SALEPRICE", "count") # count function for n
) \
.sort_values(by = ['TOTALOBS'], ascending = False) \
.reset_index() \
.query ('COUNTRY == "United States"') COUNTRY AVG_UNITPRICE AVG_LISTPRICE TOTALN TOTALOBS
0 United States 163.490316 143.727421 5886 58867.7 Summary Statistics in Python
# Summary Statistics in Python
product.GENDER.value_counts()GENDER
Male 8919
Female 6048
Name: count, dtype: int64# Encoding a Categorical Variables
product['SEX'] = product['GENDER'].map({
'Male':1,
'Female':0
})
# Defining a Function
def percentile(n):
def percentile_(x):
return x.quantile(n)
percentile_.__name__ = 'percentile_{:02.0f}'.format(n*100)
return percentile_
product [['SALEPRICE', 'UNITPRICE', 'SEX']] \
.agg(["count","mean", "std", "median", percentile(0.25), percentile(0.75)]) \
.transpose () \
.reset_index() \
.rename(columns = {'index': "Variables",
'percentile_25': 'P25',
'percentile_75': 'P75',
'count': 'n',
'mean' : 'Mean',
'median' : 'Median',
'std': 'Std'
}) \
.round(3) # rounding to two decimal places Variables n Mean Std Median P25 P75
0 SALEPRICE 14967.0 143.988 35.181 149.0 125.1 169.0
1 UNITPRICE 14967.0 164.171 22.941 159.0 149.0 179.0
2 SEX 14967.0 0.596 0.491 1.0 0.0 1.08 Reshaping Data
Two functions are widely used in python to reshape data. These functions are - melt () and pivot (), which are equivalent to pivot_longer () and pivot_wider () in R.
pd.__version__ # 2.2.3'2.2.3'product[['PRODUCTID','GENDER']].value_counts()PRODUCTID GENDER
2192 Male 135
2190 Male 132
2206 Male 123
2183 Male 123
2226 Male 123
...
2176 Female 39
2166 Female 39
2235 Female 36
2164 Female 33
2162 Female 33
Name: count, Length: 192, dtype: int64reshape = product[['PRODUCTID','GENDER']] \
.value_counts() \
.reset_index(name = 'COUNTS') \
.pivot(index = 'PRODUCTID', columns = 'GENDER', values = "COUNTS") \
.assign (TOTALSALES = lambda x: x.Female + x.Male) \
.sort_values (by = ['TOTALSALES'], ascending = False) \
.reset_index()
reshape.head(5)GENDER PRODUCTID Female Male TOTALSALES
0 2190 75 132 207
1 2213 90 114 204
2 2226 81 123 204
3 2192 66 135 201
4 2158 78 120 1989 Data Visualization
9.1 Bar Chart
bar_r = product.filter (['COUNTRY']) \
.value_counts() \
.reset_index() \
.rename (columns = {'count':'n'}) \
.sort_values (by = ['n'])
plot = (ggplot(data = bar_r,
mapping = aes(x = 'COUNTRY', y = 'n'))+
geom_bar (fill = "pink", stat = "identity")+
labs (x = 'Country',
y = 'Number of Observations'
#,title = 'Total Observations of Countries'
)
)
plot.draw(True)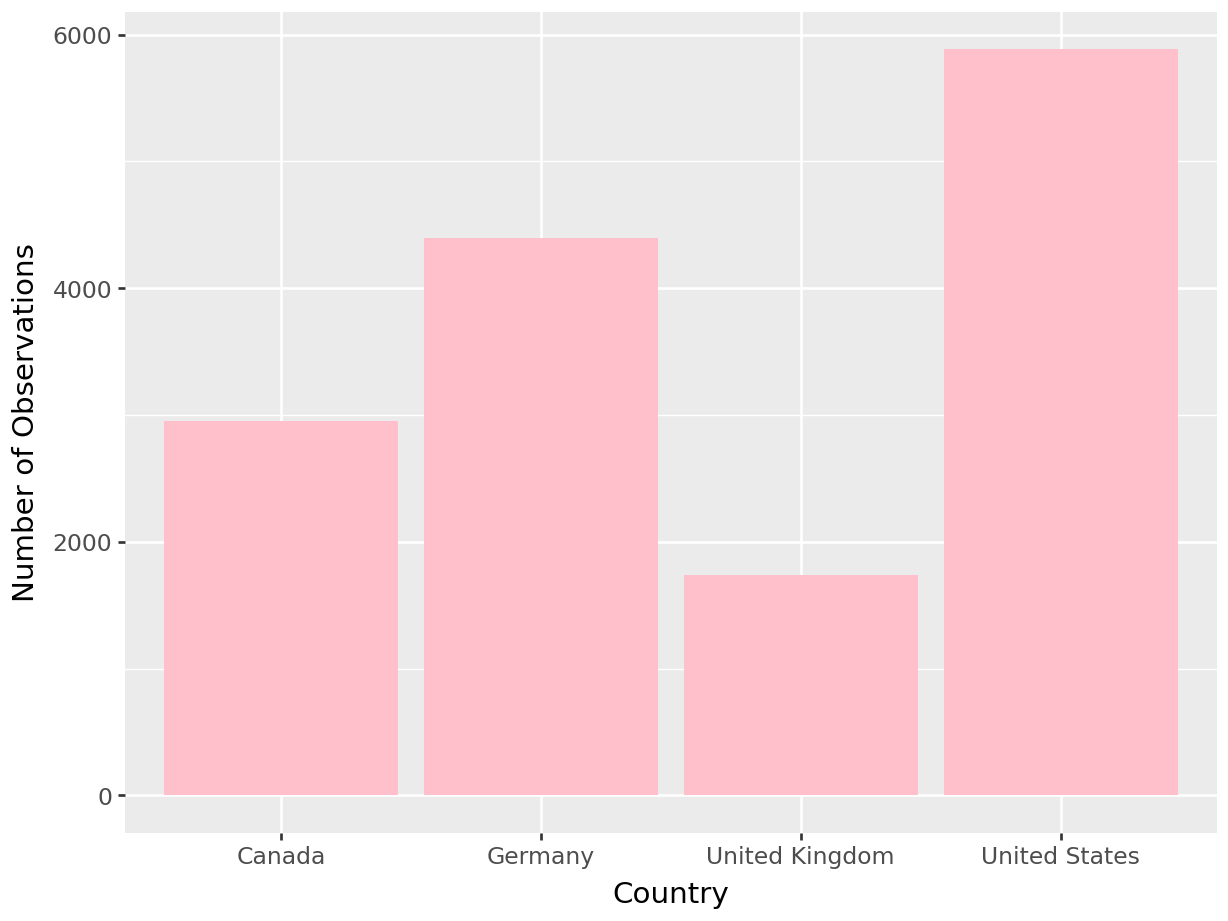
9.2 Line Chart
plot = (ggplot(product, aes(x = 'SIZE_US', y= 'UNITPRICE', color = 'GENDER'))+
facet_wrap('COUNTRY')+
geom_smooth(se = False, method = 'lm')+
labs(x = "Shoe Size (US)", y = "Price")+
theme (legend_position = "top")
)
plot.draw(True)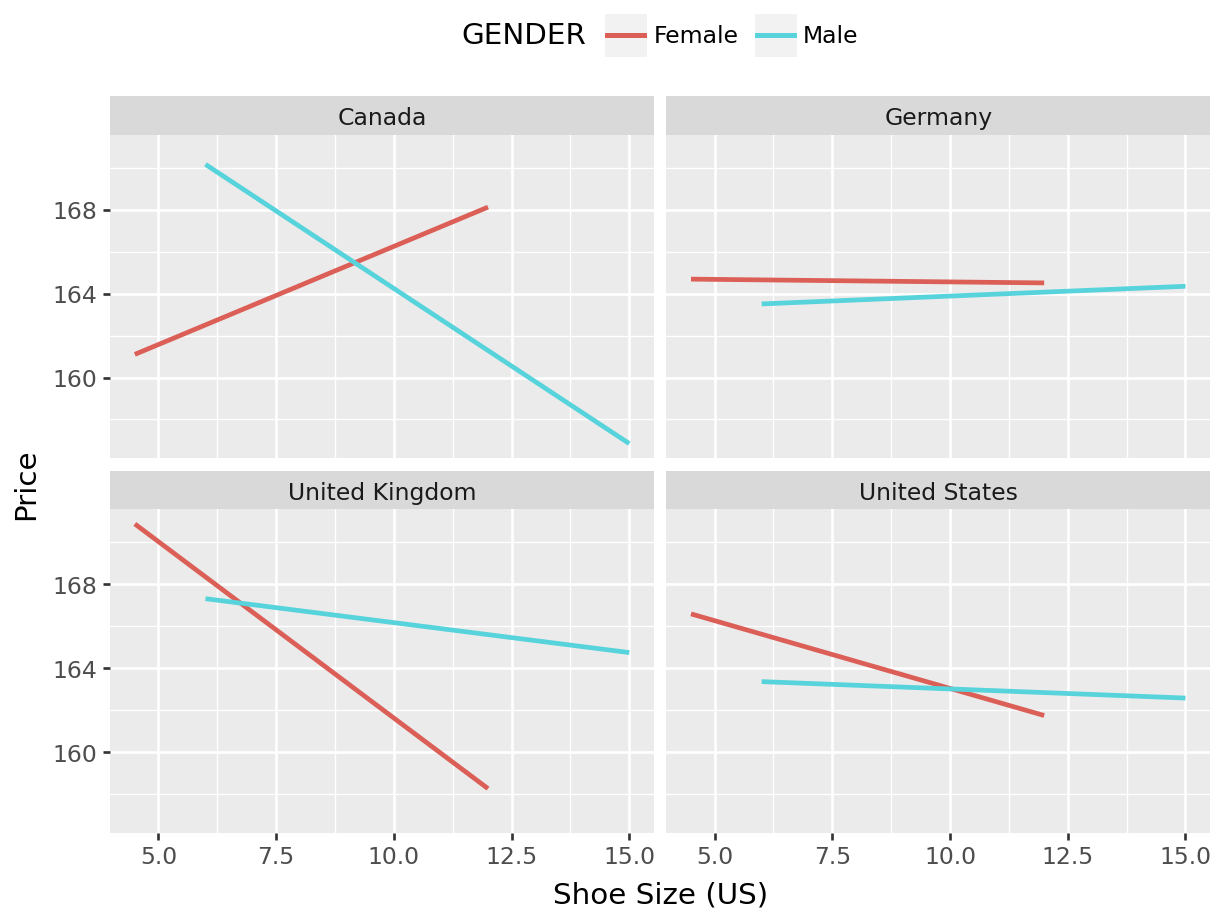
month_sales = product['MONTH'] \
.value_counts(sort = False) \
.reset_index(name = 'SALES') \
.rename (columns = {'index' : 'MONTH'})
month_sales['MONTH'] = pd.to_numeric(month_sales['MONTH'])
plot = (ggplot(month_sales, aes ("MONTH", "SALES"))
+ geom_point(color = 'blue')
+ labs(x = "Month", y = "Total Sales"
#,title = "SALES IN DIFFERENT MONTHS"
)
)
plot.draw(True)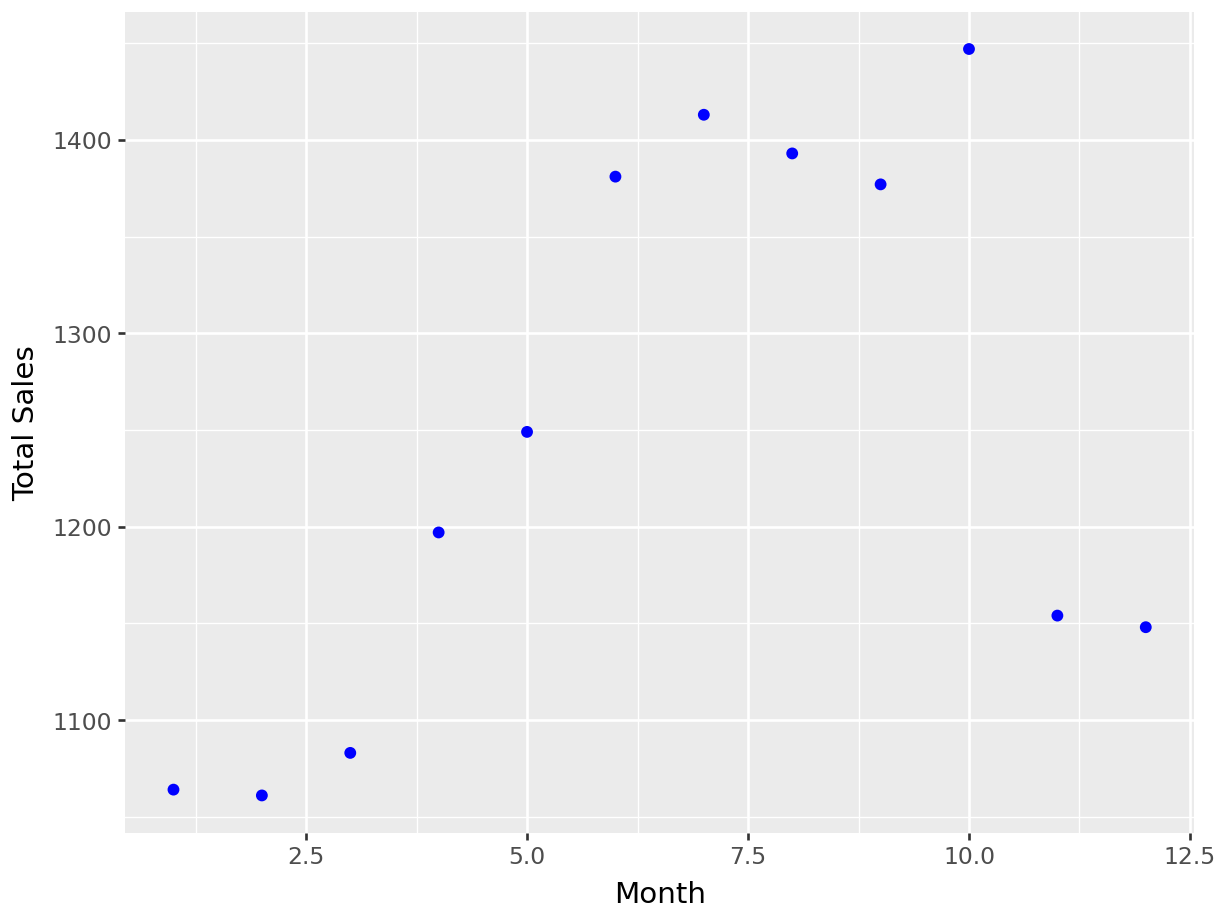
10 Conclusion
Data science is the number 1 most promising job in the US in recent years1. Many disciplines around the world are incorporating the knowledge of data science in their day to operations. The skills employers most frequently seek in data science job posting are Python, R, and SQL. It is hoped that the preliminary discussion in this project will help you to get some idea about Python in data science.
Footnotes
https://www.techrepublic.com/article/why-data-scientist-is-the-most-promising-job-of-2019/↩︎