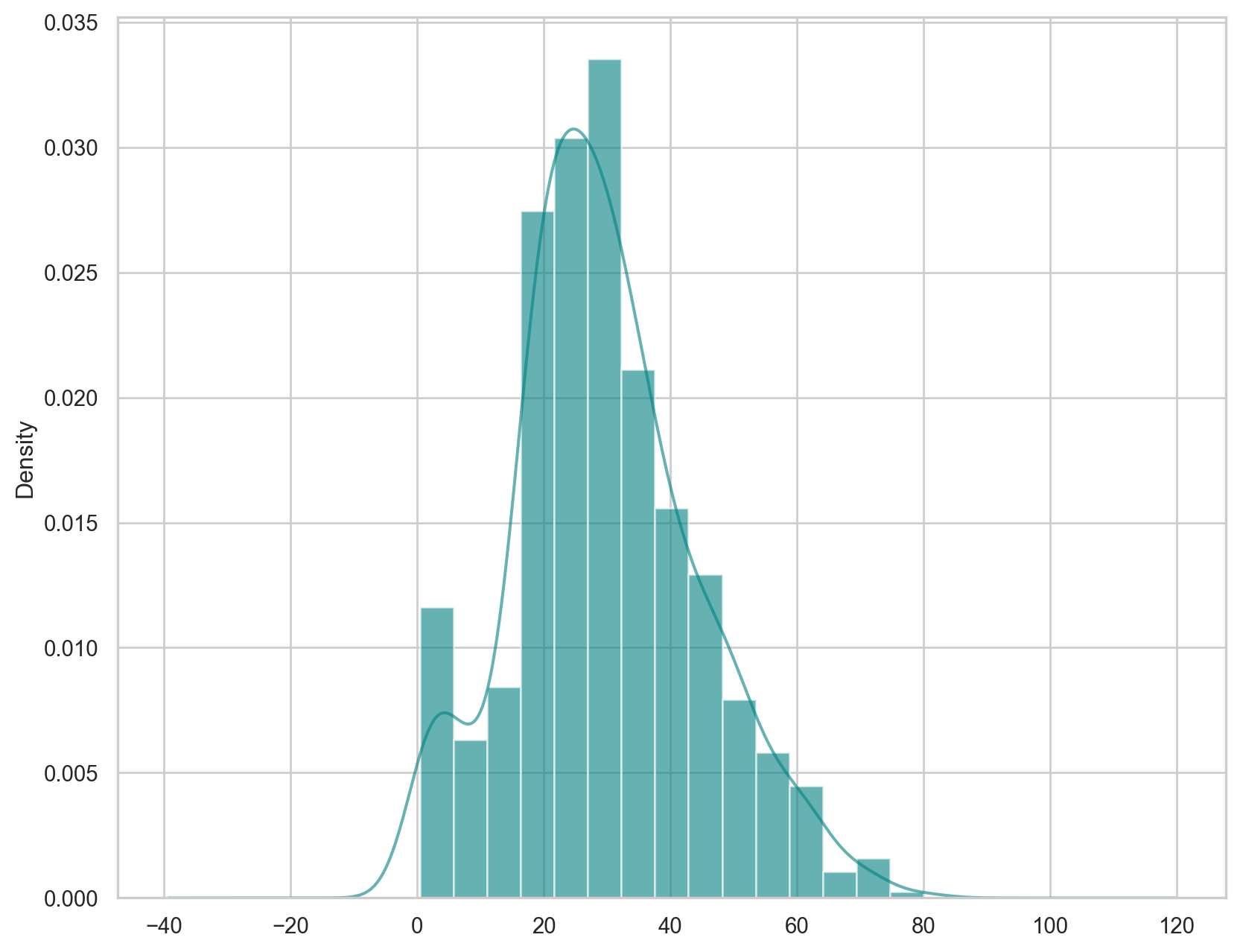
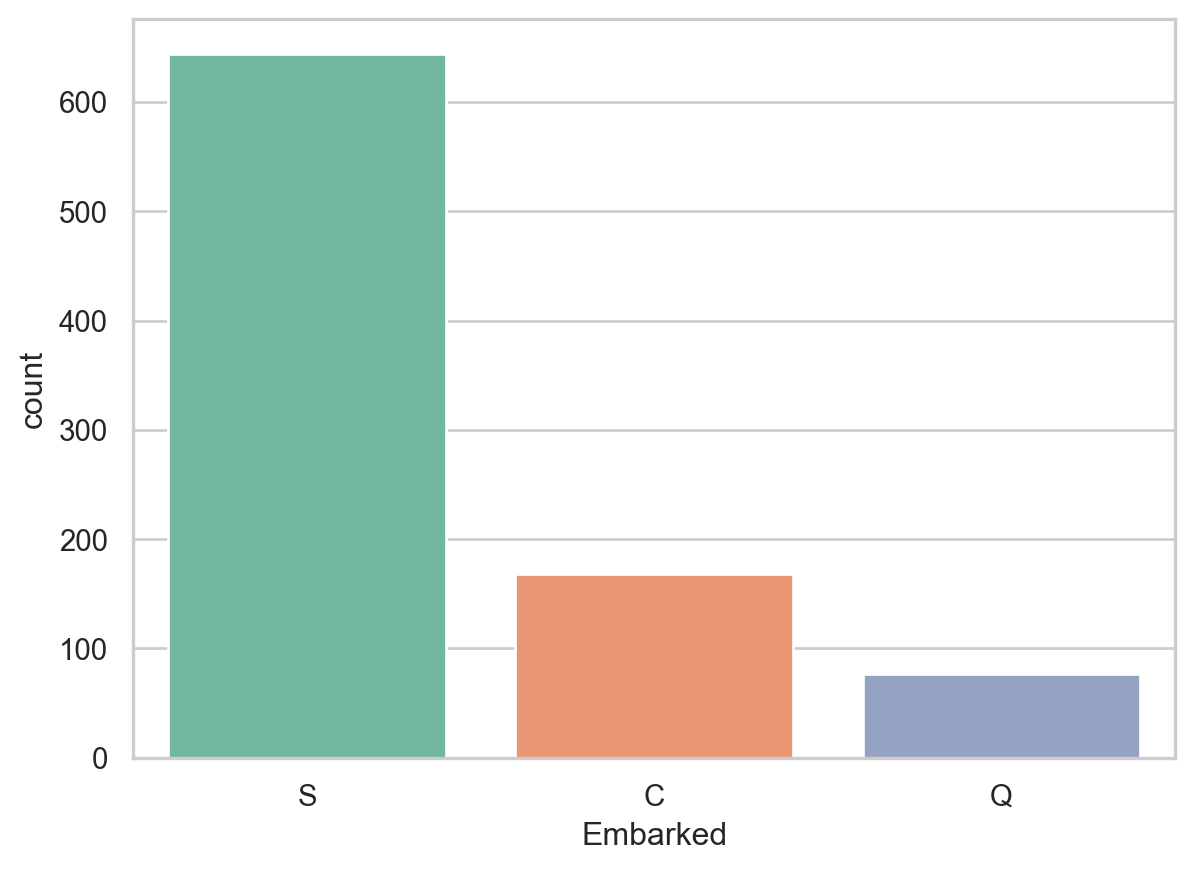
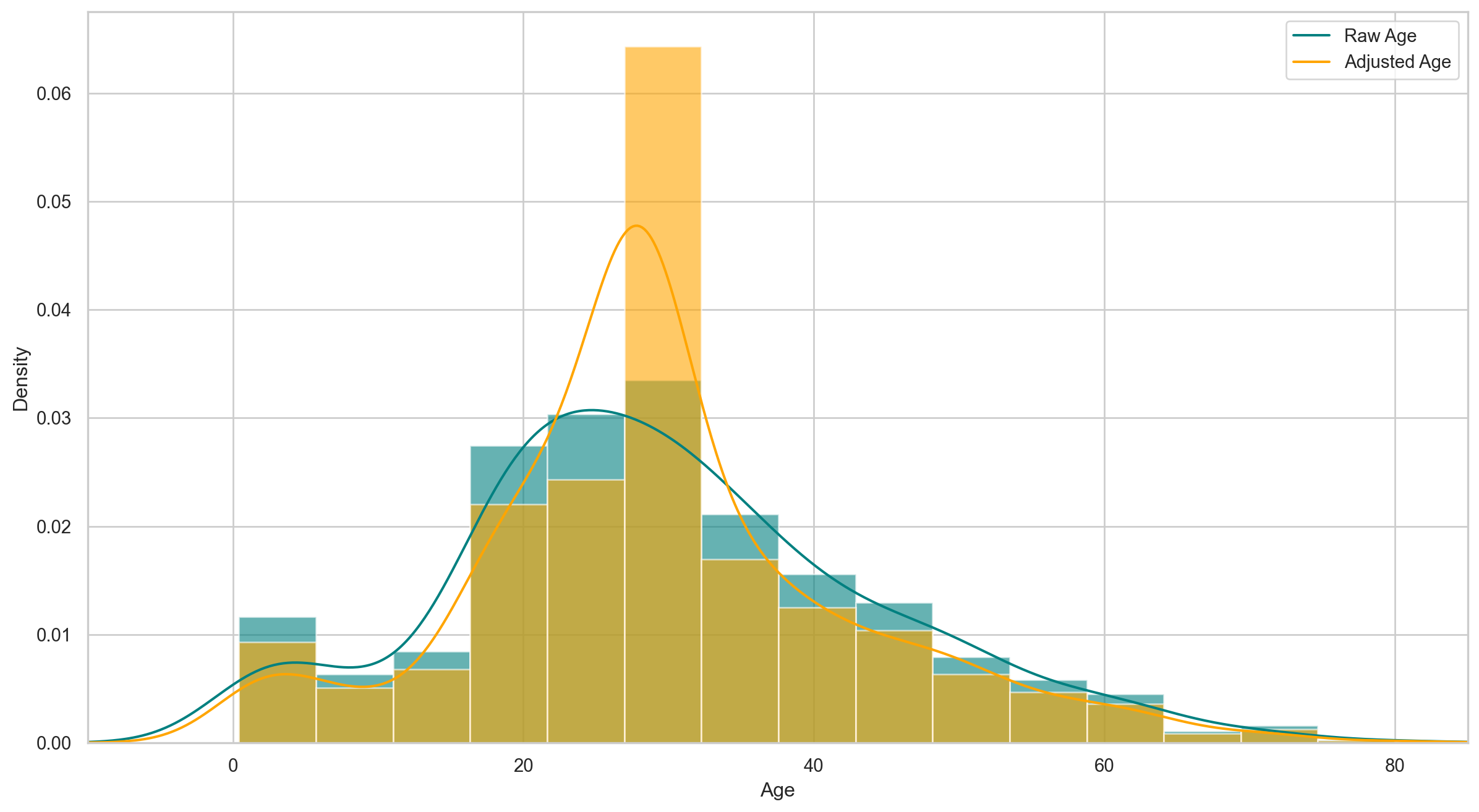
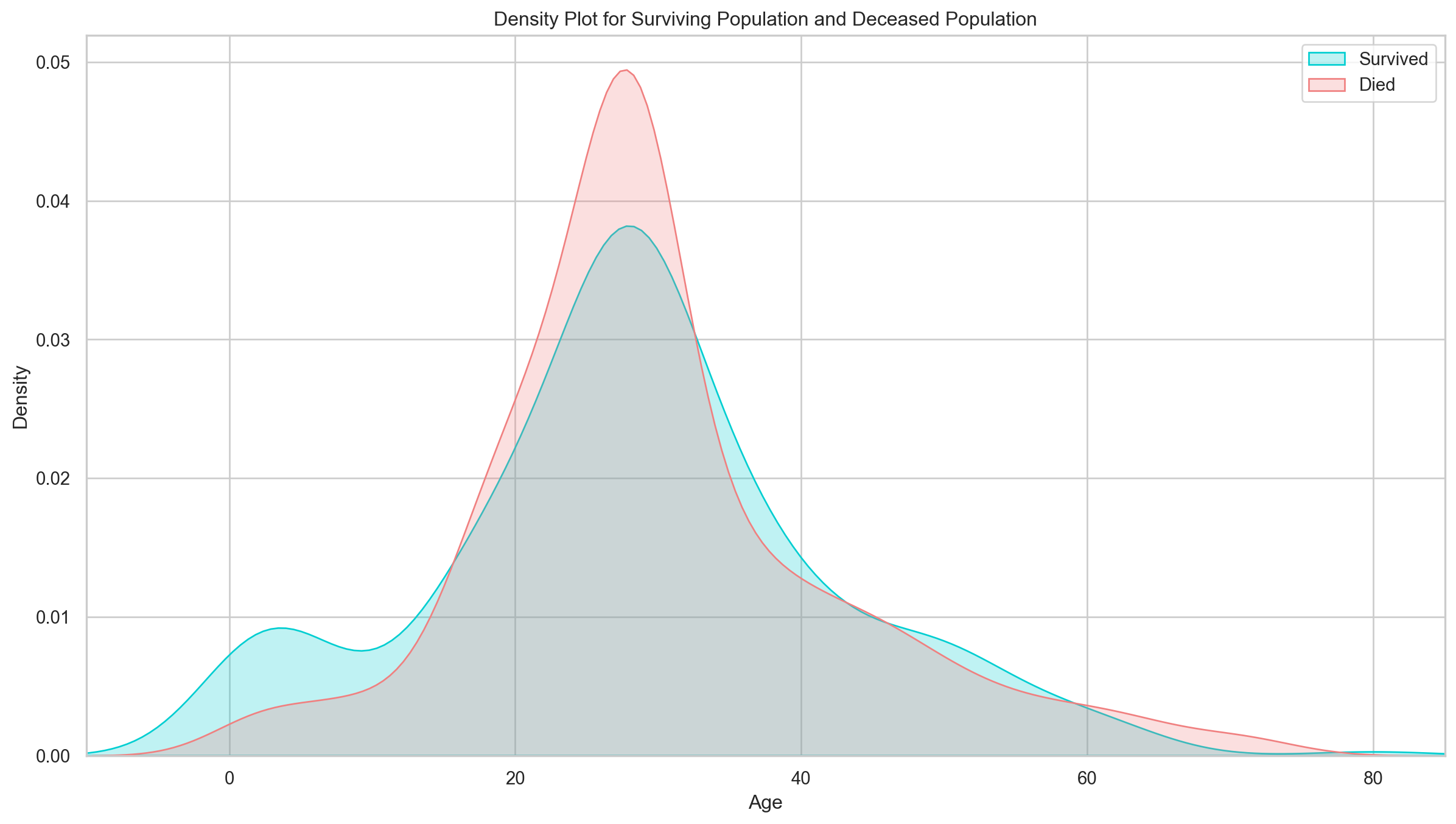
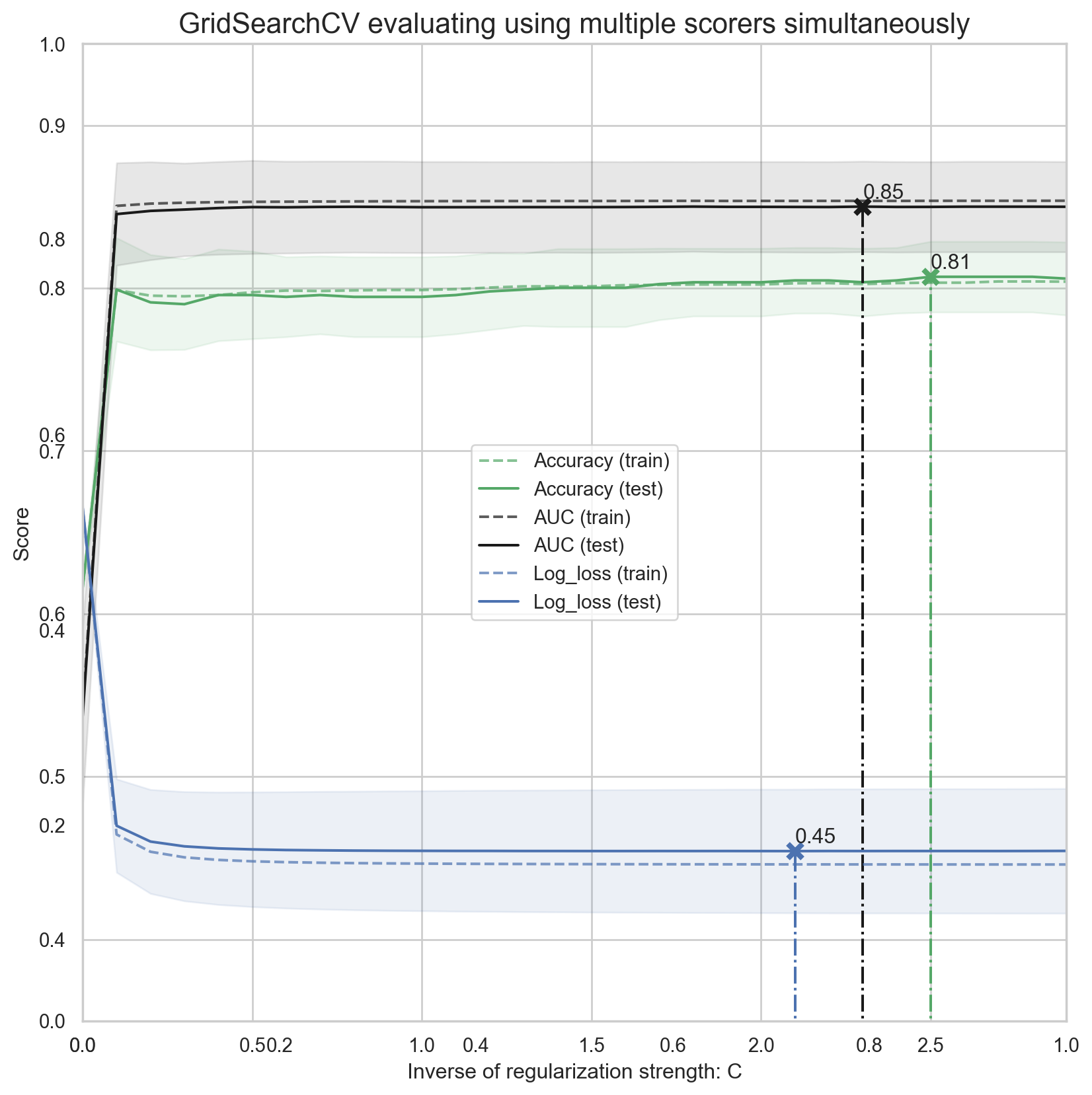
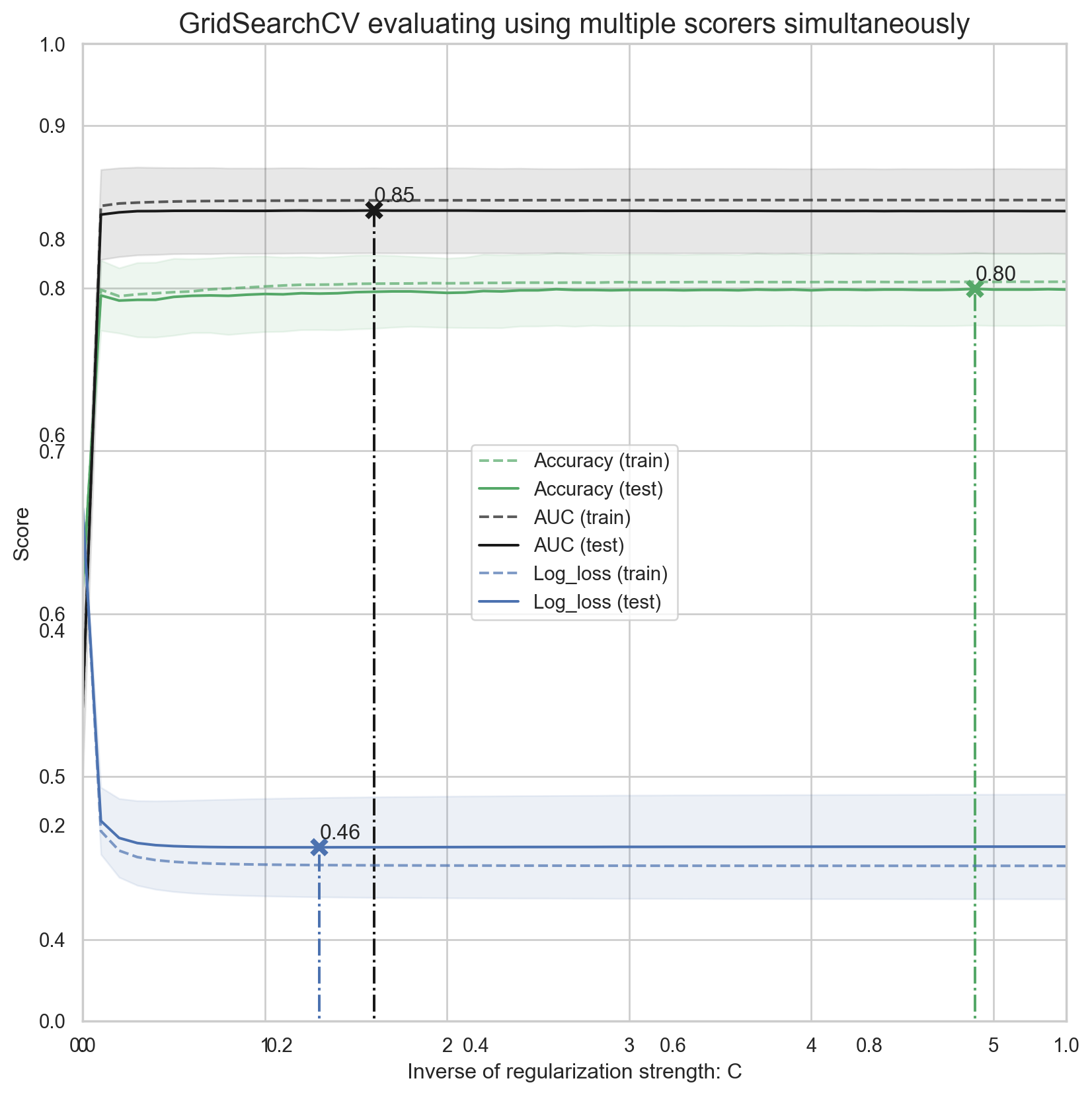
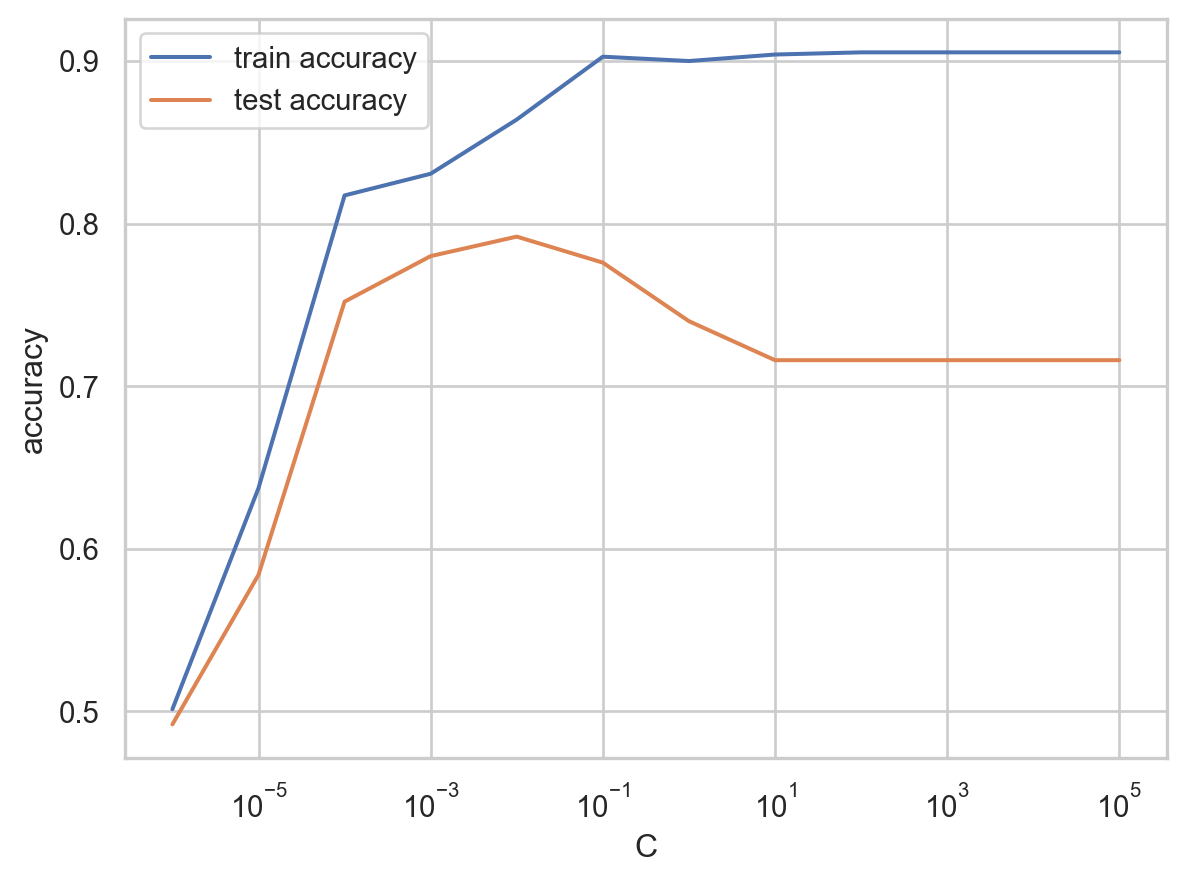
{'mean_test_score': array([0.78672909, 0.78672909, 0.78672909, 0.79009988, 0.78560549,
0.78561798, 0.78790262, 0.79574282, 0.79463171]),
'std_test_score': array([0.02859935, 0.02859935, 0.02859935, 0.02989151, 0.02604354,
0.02546772, 0.03370206, 0.02689652, 0.02691683]),
'split0_test_score': array([0.81111111, 0.81111111, 0.81111111, 0.81111111, 0.81111111,
0.8 , 0.76666667, 0.78888889, 0.77777778]),
'split1_test_score': array([0.79775281, 0.79775281, 0.79775281, 0.79775281, 0.76404494,
0.75280899, 0.76404494, 0.79775281, 0.79775281]),
'split2_test_score': array([0.76404494, 0.76404494, 0.76404494, 0.76404494, 0.76404494,
0.78651685, 0.7752809 , 0.7752809 , 0.7752809 ]),
'split3_test_score': array([0.84269663, 0.84269663, 0.84269663, 0.85393258, 0.83146067,
0.83146067, 0.84269663, 0.85393258, 0.85393258]),
'split4_test_score': array([0.79775281, 0.79775281, 0.79775281, 0.79775281, 0.79775281,
0.79775281, 0.79775281, 0.7752809 , 0.7752809 ]),
'split5_test_score': array([0.7752809 , 0.7752809 , 0.7752809 , 0.78651685, 0.78651685,
0.78651685, 0.78651685, 0.78651685, 0.7752809 ]),
'split6_test_score': array([0.76404494, 0.76404494, 0.76404494, 0.76404494, 0.76404494,
0.76404494, 0.76404494, 0.76404494, 0.7752809 ]),
'split7_test_score': array([0.74157303, 0.74157303, 0.74157303, 0.74157303, 0.74157303,
0.74157303, 0.74157303, 0.7752809 , 0.7752809 ]),
'split8_test_score': array([0.80898876, 0.80898876, 0.80898876, 0.80898876, 0.80898876,
0.80898876, 0.85393258, 0.83146067, 0.83146067]),
'split9_test_score': array([0.76404494, 0.76404494, 0.76404494, 0.7752809 , 0.78651685,
0.78651685, 0.78651685, 0.80898876, 0.80898876]),
'n_features': array([1, 2, 3, 4, 5, 6, 7, 8, 9])}